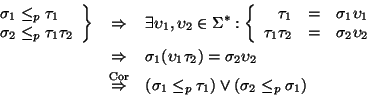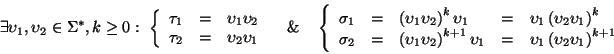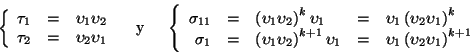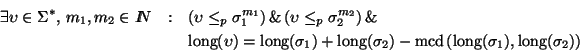Primeramente presentamos condiciones necesarias y suficientes para comparar cadenas y subcadenas.
Teorema 2.1 (Levi)
Sean
tales que
.
Entonces se cumplen las implicaciones siguientes:
1.
2.
3.
Gráficamente resulta muy clara la validez del teorema y por eso omitimos su demostración formal.
Como una consecuencia directa de este teorema resulta el siguiente
Corolario 2.1
Si
son tales que
entonces
es un prefijo de
o, recíprocamente,
es un prefijo de .
Recordamos que una relación de orden ``'' en un conjunto S es una relación binaria
tal que es reflexiva, transitiva y antisimétrica. Esto último significa que
Del último corolario se ve fácilmente que la relación de prefijo:
es, efectivamente, un orden en .
Hemos visto que
no es conmutativo. Veremos a continuación algunas proposiciones relativas al orden de prefijo y a la contención, en general, entre cadenas.
Proposición 2.5
Si
son tales que
y
entonces
o
.
En efecto, las siguientes implicaciones son todas verdaderas:
En el siguiente teorema veremos una condición necesaria para que una palabra sea a la vez prefijo y sufijo de alguna otra. Es evidente que la condición que ahí se establece es también suficiente.
Teorema 2.2
Sean
tales que
es prefijo y sufijo de ,
es decir
Entonces,
En efecto, consideremos dos casos, según se comparen entre sí las longitudes de las palabras
y .
:
Ya que
,
por el teorema de Levy se tiene que
es un prefijo de .
Se ve pues que
tal que
y
.
El teorema se cumple tomando
y k=0.
:
Probemos el teorema por inducción en
.
Para
el teorema se cumple pues se está en el caso anterior.
Supongamos ahora que
y que el teorema se cumple para toda palabra
tal que
.
Ya que
,
por el teorema de Levy se tiene que, para alguna
Por la hipótesis de inducción
y con esto queda demostrado el teorema.
Con el siguiente teorema vemos cuándo dos palabras dadas son ambas múltiplos de una misma partícula.
Teorema 2.3
Sean
.
Las siguientes aseveraciones son equivalentes:
1.
Ambas
son múltiplos de una misma partícula, es decir,
2.
Las palabras
y
poseen sendos múltiplos con un prefijo común de longitud
En símbolos,
Escribamos
,
i=1,2.
:
Supongamos que
,
i=1,2. Para i=1,2, hagamos
donde
denota al entero más chico por encima de x.
Tenemos pues que, para i=1,2,
.
Puesto que
,
se tiene que
contiene a la palabra
,
la cual tiene longitud
:
Supongamos que
es un prefijo común de
,
i=1,2, de longitud
.
Supongamos, sin pérdida de generalidad, que
,
e, inicialmente, que
.
Escribamos
.
Como ambos
y
poseen un prefijo común de longitud k1+k2-1, se tiene que
En particular,
,
.
Y por tanto,
,
.
Ahora bien, como
,
tenemos que el conjunto de índices
coincide con todo el intervalo [0,k1-1]. Por tanto, tenemos que
.
Así pues, resulta válida la condición 1., con
,
la cual es una palabra de longitud 1.
En el caso de que
,
consideremos el alfabeto
.
Entonces
y ,
vistas como palabras en
,
tienen longitud
y
respectivamente, y aquí,
.
Así, este caso se reduce al anterior y consecuentemente también en este caso resulta válida la condición 1.
Para concluir esta sección veamos una condición necesaria para que dos palabras conmuten bajo la operación de concatenación.
Proposición 2.6
Sean
dos palabras tales que
.
Entonces
En efecto, supongamos que
y que
.
Por el Teorema de Levy, existe una palabra
tal que
Consecuentemente,
y
conmutan. Así, que por la misma razón,
Consecutivamente, en tanto que
,
se tendrá que ha de existir una
tal que
Así pues,
donde
.
Igualmente,
donde
.
Reiterando este procedimiento construimos una sucesión de palabras
tal que para todo k,
Observe el lector la similitud que existe entre este procedimiento y el cálculo del máximo común divisor de
mediante el Algoritmo de Euclides.
Como las longitudes de las palabras
están decreciendo, en un momento se harán cero. Sea
la última palabra no nula en esa sucesión. Pues bien, se tiene que
.
Siguiente:Orden lexicográficoUn nivel arriba:Relaciones de orden Anterior:Relaciones de ordenGuillermo Morales-Luna
2000-06-27