Una clase de lenguajes
es un álgebra si es cerrada por unión y complemento y si contiene al conjunto vacío. Es decir, si se cumplen las propiedades
En una clases de lenguajes, además de caracterizar la solubilidad de los problemas de la palabra y de derivación, mencionados en la Introducción del curso, también es importante decidir si acaso una clase dada de lenguajes en un álgebra.
Por ejemplo, la clase de lenguajes regulares sobre un alfabeto finito forma un álgebra de conjuntos.
La clase de lenguajes recursivamente enumerables, es decir, aquellos que son generados por gramáticas irrestrictas, contiene al conjunto vacío, y la unión y la intersección de cualesquiera dos lenguajes en la clase están en la clase, sin embargo no ocurre lo mismo para la operación de complementación.
En general, si
es un operador de aridad k, que transforma k lenguajes dados en algún otro lenguaje, un problema importante para una clase
de lenguajes es decidir cuándo esa clase es cerrada bajo el operador, es decir, cuándo rige la implicación:
La siguiente observación se sigue inmediatamente de las conocidas Leyes de De Morgan, válidas en el álgebra de conjuntos:
Observación 3.1
Una clase de lenguajes
es un álgebra si y sólo si
1.
contiene al lenguaje vacío, ,
2.
es cerrada bajo la unión, y
3.
es cerrada bajo la operación de complementación.
Hemos ya visto algunos de los operadores más usuales entre lenguajes:
Unión.
:
palabras que están en L1 o en L2.
Intersección.
:
palabras que están en ambos lenguajes L1 y L2.
Diferencia.
:
palabras que están en L1 pero no en L2.
Complemento.
:
palabras en el diccionario que no están en L.
Concatenación.
:
palabras formadas al concatenar partículas en L1 y en L2.
0-ésima potencia.
:
mónada consistente de la palabra vacía.
m-ésima potencia (m>0).
:
palabras que se forman al concatenar m partículas en L.
Operador ``estrella'' (de Kleene).
:
palabras que se forman al concatenar un conjunto finito de partículas en L, incluída la palabra vacía.
Operador ``más''.
:
palabras que se forman al concatenar un conjunto finito de partículas en L.
Mas también los siguientes serán utilizados en este curso:
i-ésima m-ava parte.
A cada palabra del lenguaje se la divide en partes iguales y se toma la i-ésima:
palabras que se forman al ``dividir'' en m partes de igual longitud a palabras en L,
.
m-ésimas repeticiones.
:
palabras que se forman al concatenar m copias de una misma partícula en L.
Raíz m-ésima.
:
palabras tales que al concatenar m copias de ellas producen una palabra en L. Por tanto,
.
Cociente izquierdo.
:
prefijos que con sufijos en L2 dan palabras en L1.
Derivada izquierda.
:
prefijos que con
dan palabras en L.
Cociente derecho.
:
sufijos que con prefijos en L2 dan palabras en L1.
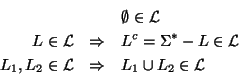
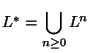 :
palabras que se forman al concatenar un conjunto finito de partículas en L, incluída la palabra vacía.
:
palabras que se forman al concatenar un conjunto finito de partículas en L, incluída la palabra vacía.
![$L=\left(\sqrt[m]{L}\right)^{(m)}$](img345.gif) .
.