Constructing interpolation polynomials based on the characteristic equation leads to a family of orthogonal idempotents resolving the identity. In the confluent case, there are supplementary nilpotent matrices which take up the slack left by the redundant eigenvectors. Since an idempotent satisfies the equation ![]() its eigenvalues can only be
its eigenvalues can only be ![]() or
or ![]() ; similarly
; similarly ![]() , can be the only eigenvalue of a matrix which satisfies
, can be the only eigenvalue of a matrix which satisfies ![]() . That is the way to get a concise derivation of Sylvester's formula, without going through the steps of constructing a basis, which is the frame of reference likely to be required in applications.
. That is the way to get a concise derivation of Sylvester's formula, without going through the steps of constructing a basis, which is the frame of reference likely to be required in applications.
Let ![]() map a vector
map a vector ![]() to
to ![]() , which may or may not be parallel to
, which may or may not be parallel to ![]() , depending on fortune. If it is not, map this new vector into
, depending on fortune. If it is not, map this new vector into ![]() , and so on. Eventually the result has to be dependent on the foregoing vectors, because of the of the dimensionality.
, and so on. Eventually the result has to be dependent on the foregoing vectors, because of the of the dimensionality.
The coefficients of the dependence can be transferred to the matrix powers (supposing, formaly, that a zero power is the unit matrix), resulting in a polynomial in ![]() :
:
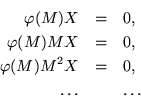
Rather than trusting to luck, it would be possible to start with a basis consisting of vectors ![]() comprising the columns of a matrix
comprising the columns of a matrix ![]() to obtain a sequence of polynomials for which
to obtain a sequence of polynomials for which
![]() . Not knowing whether they have common factors, it would be necessary to say that
. Not knowing whether they have common factors, it would be necessary to say that
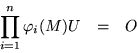
Just as in the case of repeated roots of the determinantal equation, there are messy cases to be accounted for when a polynomial of lesser degree suffices, or none of the starting vectors leads up to a full basis; as an extreme example, consider finding eigenvectors for the zero matrix or the unit matrix.
If the coefficient of ![]() in
in ![]() is not zero, implying that the vector chosen for the power search was a good choice, we could set
is not zero, implying that the vector chosen for the power search was a good choice, we could set ![]() aside, assume its coefficient to be 1, and take
aside, assume its coefficient to be 1, and take ![]() out of the remaining polynomial as a factor, to get
out of the remaining polynomial as a factor, to get
This construction of the characteristic polynomial leaves the impression that the set of powers of a matrix is a vector space of the same dimension (or less) as the space on which the matrix itsef operates. Of course the set of all linear mappings from a vector space to itself is another vector space, whose dimension would have to be the square of the original dimension. Polynomials in a single matrix constitute a subspace of Linear(V, V); one might speculate whether there could be be another matrix, generating a second polynomial subspace, such that the entire set of linear mappings were expressible as polynomials in just those two variables.